
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- 스케줄링
- 파일시스템 구현
- 다이나믹프로그래밍
- 쓰레드
- 병행성
- 자료구조
- 알고리즘
- 멀티쓰레드
- OS
- 디자인패턴
- 다이나믹 프로그래밍
- directx
- I/O장치
- 락
- 운영체제
- 그리디알고리즘
- 컨디션 변수
- 멀티프로세서
- 영속성
- 렌더링 파이프라인
- DirectX 12
- Direct12
- DirectX12
- 병행성 관련 오류
- 프로그래머스
- 동적계획법
- 그리디 알고리즘
- codility
- 타입 객체
- 백준
- Today
- Total
기록공간
[DirectX 12] 렌더링 파이프라인 - 2 본문
입력 조립기 단계(Input Assembler, IA)
입력 조립기 단계는 메모리에서 기하 자료(정점, 인덱스)를 읽어서 기본 도형(삼각형, 선분 등)을 조립한다.
정점(Vertex)
수학적으로, 한 삼각형의 정점은 두 변이 만나는 점이다. 선분의 경우 선분의 양 끝점이 정점이고, 하나의 점의 경우에는 그 점 자체가 정점이다.

Direct3D의 정점은 본질적으로 공간적 위치 이외의 정보도 담을 수 있으며, 이를 통해 좀 더 복잡한 렌더링 효과를 낼 수 있다. 예를 들면, 조명을 구현하기 위해 정점에 법선 벡터(normal vector)를 추가하며, 텍스처 적용을 위해 정점에 텍스처 좌표를 추가한다. 또한 Direct3D는 응용 프로그램이 자신만의 정점 형식을 정의할 수 있는(성분들을 직접 정의할 수 있는) 유연성을 제공한다
기본 도형 위상 구조(Primitive topology)
정점들은 정점 버퍼라고 하는 Direct3D 자료구조 안에 담겨서 렌더링 파이프라인에 묶인다. 정점 버퍼는 그냥 일단의 정점들을 연속적인 메모리에 저장하는 자료구조일 뿐이다. 정점 버퍼 자체는 그 정점들을 어떤 식으로 조합해서 기본 도형을 생성할 것인지 말해주지 않는다. 정점 버퍼 안에 담긴 정점들을 두 개씩 엮어서 선분을 형성할 수도 있고, 세 개씩 엮어서 삼각형을 형성할 수도 있다. 이 형성 방식을 Direct3D에게 알려주는 데에 쓰이는 수단이 기본 도형 위상 구조이다. 다음은 기본 도형 위상 구조를 지정하는 메서드와 기본 도형 위상 구조들을 정의한 열거형이다.
void ID3D12GraphicsCommandList::IASetPrimitiveTopology(
D3D12_PRIMITIVE_TOPOLOGY PrimitiveTopology
);
이 메서드를 호출하여 기본 도형 위상 구조를 설정하면 다음 호출이 있을 때까지 그 위상 구조가 적용된다. 예외가 있겠지만 거의 대부분은 삼각형 목록(TRIANGLELIST)을 기본 도형 위상 구조로 사용한다.(대부분의 메쉬는 수많은 삼각형으로 근사하여 표현하기 때문이다.)
1. 점 목록
D3D12_PRIMITIVE_TOPOLOGY_POINTLIST를 지정한다. 모든 정점은 개별적인 점으로 그려진다.

2. 선 목록
D3D12_PRIMITIVE_TOPOLOGY_LINELIST를 지정한다. 매 정점 두 개가 개별적인 하나의 선분을 형성한다. 2n개의 정점으로 n개의 선분이 만들어진다.
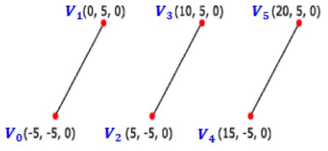
3. 선 띠
D3D12_PRIMITIVE_TOPOLOGY_LINESTRIP을 지정한다. 선 띠의 경우 정점들이 차례로 이어져 일련의 선분들이 그려진다. 선 띠는 선 목록과 다르게 정점을 따라 자동으로 선분이 이어진다.

4. 삼각형 목록
D3D12_PRIMITIVE_TOPOLOGY_TRIANGLELIST를 지정한다. 매 정점 세 개가 하나의 개별적인 삼각형을 형성한다. 3n개의 정점으로 n개의 삼각형이 만들어진다.

5. 삼각형 띠
D3D12_PRIMITIVE_TOPOLOGY_TRIANGLESTRIP을 지정한다. 정점들이 연결되어 일련의 삼각형들을 형성한다. n개의 정점으로 n - 2개의 삼각형들이 만들어진다.
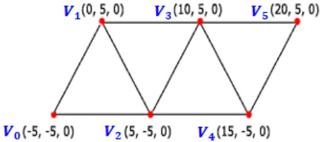
색인(Index)
앞서 말했지만 3차원 물체의 기본 구축 요소는 삼각형이다.
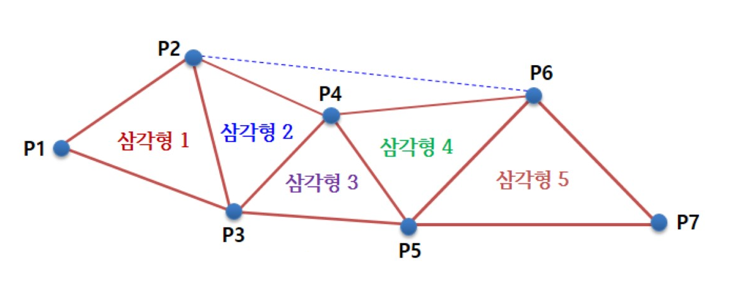
다음과 같은 삼각형들이 있다고 하자. 삼각형을 유심히 살펴보면 다수의 정점들을 공유하고 있다. 삼각형 1과 삼각형 2는 정점 P2와 P3를 공유하고 있다. 즉 2개의 정점에서 2번 중복이 있다. 심지어 삼각형 2, 3, 4는 정점 P4를 공유하고 있어 하나의 정점이 3번 중복된다. 이 중복 현상은 물체가 더 복잡해져 많은 삼각형으로 표현해야 하는 경우 더 심각해진다.
정점들의 중복이 바람직하지 않은 이유는 크게 두 가지이다.
-
메모리 요구량 증가. (같은 정점을 여러 번 저장하기 때문에)
-
그래픽 하드웨어 처리량 증가. (같은 정점 자료를 여러 번 처리하기 때문에)
따라서 삼각형 목록에서 중복 정점들을 제거하는 방법은 가치가 있는 일이다. 이 해법을 색인이 제공한다. 고유한 정점들로 정점 목록을 만들면, 어떤 정점을 어떤 순서로 사용해서 삼각형을 형성하는지를 그 정점들의 색인을 나열하여 지정하면 된다.

Vertex v[7] = {P1, P2, P3, P4, P5, P6, P7};UINT indexList[] = {
0, 1, 2, // 삼각형 1
1, 3, 2, // 삼각형 2
2, 3, 4, // 삼각형 3
3, 5, 4, // 삼각형 4
4, 5, 6 // 삼각형 5
};그래픽 카드는 정점 목록의 고유한 정점들을 처리한 후, 색인 목록을 이용해서 정점들을 조합해 삼각형을 형성한다. 대신 색인들의 중복이 생겼지만 두 가지 이유로 큰 문제가 되지 않는다.
-
색인은 그냥 정수이므로 정점 구조체보다 적은 양의 메모리를 차지한다.
-
정점 캐시 순서가 좋은 경우 그래픽 하드웨어는 중복된 정점들을 처리하지 않아도 된다.
정점 셰이더 단계(Vertex Shader, VS)
입력 조립기 단계에서 기본 도형들을 조립한 후에는 정점들이 정점 셰이더 단계로 입력된다. 화면에 그려질 모든 정점은 정점 셰이더를 거쳐 간다. 개념적으로 하드웨어에서 다음과 같은 일이 일어난다고 생각하면 된다.
for(UINT i = 0; i < numVertices; ++i)
outputVertex[i] = VertexShader (inputVertex[i]);정점 셰이더 함수의 구체적인 내용은 프로그래머가 구현해서 GPU에 제출한다. 그 함수는 각 정점에 대해 GPU에서 실행되기 때문에 아주 빠르다.
변환 조명, 변위 매핑 등 수많은 특수 효과를 정점 셰이더에서 수행할 수 있다. 정점 셰이더 입력 정점 자료는 텍스처라든가 변환 행렬, 라이트 정보 등 GPU 메모리에 담긴 다른 자료에도 접근할 수 있다.
지역 공간과 세계 공간
영화 제작팀에서 축소된 철로 세트를 만들어야 한다고 상상해보자. 구체적으로, 주어진 일은 작은 다리를 하나 만드는 것이다. 그런데 철로 세트에서 직접 다리를 만들면 실수로 다른 지형지물을 망가뜨릴 위험이 있다. 따라서 세트에서 좀 떨어진 작업대에서 다리를 다 만든 후 그 다리를 철로 세트로 가져가 적절한 위치에 적절한 방향으로 설치하는 것이 바람직하다.
3차원 장면을 위한 물체 모형을 만들 때도 이러한 작업을 한다. 즉, 물체의 기하구조를 장면 전역의 좌표계를 기준으로 직접 구축하는 것이 아니라 물체 자신의 지역 좌표계를 기준으로 구축하는 것이다. 전자의 좌표계를 세계 공간(world space)이라 부르고 후자를 지역 공간(local space)이라고 부른다.(이제 나올 키워드들은 보통 영어로 부른다)
local space에서 작업을 하면 좌표계 원점을 물체의 중심 가까이에 둘 수 있고 좌표축들을 물체에 맞게 정렬할 수 있기 때문에 편하다. local space에서 3차원 모형 정점들을 모두 정의했다면 그것들을 세계 공간에 적절한 위치와 방향으로 배치해야 한다. 이를 위해 local space와 world space 관계를 정의할 수 있어야 한다. 즉, world space 기준으로 좌표 변경 변환을 수행해야 한다.

이를 세계 변환(world transform)이라고 부르고, 해당 변환 행렬을 세계 행렬(world matrix)라고 부른다. 장면의 모든 물체에는 각자의 world matrix가 있다. 각 물체를 world transform 하고 나면 모든 물체의 모든 좌표가 동일한 좌표계(세계 공간)를 기준으로 한 것이 된다.
변환 행렬은 어떻게 정의되는지 한번 살펴보자. 공간을 나타내는 벡터에 행렬을 곱한다는 것은 벡터를 변환하는 것이다. 즉, 행렬이 곧 변환을 해주는 매개체이다.

행렬에서 (1, 1) (2, 2) (3, 3) 위치의 값들은 크기를 나타낸다. 각각 이 값들을 조정하고 물체를 나타내는 정점 벡터들과 곱하면 물체가 x축, y축, z 축으로 크기가 늘거나 줄어든다. 이 행렬을 Scale(S)이라고 부르겠다.

그리고 각 축마다 회전도 표현이 가능하다.

여기서 세타 값을 건드린 후 물체 정점 벡터들과 곱하면 물체가 세타 값만큼 x, y, z 축으로 회전한다. x, y, z 축 모두 회전하고 싶다면 각각의 세타 값을 지정한 후 위 3개의 행렬을 차례대로 곱해주면 된다. 그러므로 x축 회전 행렬 * y축 회전 행렬 * z 축 회전 행렬의 값을 Rotate(R)라고 부르겠다.
이제 크기와 회전을 변환하였으니 이동을 변환할 차례이다. 하지만 3x3 행렬은 평행이동을 표현할 수 없다. 왜냐하면 벡터의 특성 때문이다. 벡터는 위치와 무관하게 오직 방향과 크기만 서술하는 것이기 때문에 이동이 의미가 없다. 즉, 벡터는 이동에 대해 불변하고, 이동은 오직 점에만 적용된다. 그렇기 때문에 우리는 동차 좌표계를 사용하여 점과 벡터를 동일한 방식으로 다룰 수 있게 해야 한다.
동차 좌표계는 x, y, z에서 w를 추가한 것이다. 4차원 벡터 (x, y, z, w)가 있다면 이는
x1 = x/w, y1 = y/w, z1 = z/w를 한 (x1, y1, z1)과 동차이다. 즉, 4차원 벡터의 x, y, z를 w로 나누는 작업은 4차원 벡터를 3차원 벡터로 투영(Projection)하는 것이다. w가 1인 경우 3차원 벡터로 직접 대응된다. 4차원 벡터의 w값을 0으로 설정하는 경우 이동 변환은 적용되지 않는다. 동차 좌표계를 사용하면 평행이동을 표현하기 위한 행렬은 다음과 같다.
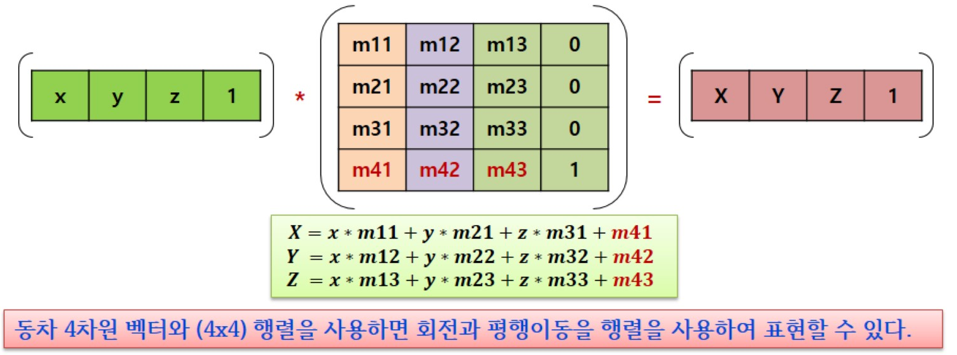

이와 같은 평행이동 행렬을 Transform(T)이라고 부르겠다.
이제 모든 변환들을 살펴봤으니 종합해주면 된다. 크기, 회전, 이동 순으로 변환 행렬을 곱한 값을 물체의 정점 벡터와 곱해주면 물체를 올바르게 world space상에 놓을 수 있게 된다. 즉, 월드 변환 행렬(world transform matrix)을 W라고 했을 때 W = S * R * T이다.


시야 공간
3차원 장면의 2차원 이미지를 만들어 내려면 장면에 가상의 카메라를 배치해야 한다. 그 카메라는 world에서 보이는 영역을 결정한다. 그 영역이 바로 프로그램에서 2차원 이미지로 만들어 모니터에 표시할 영역이다.

위 그림처럼 가상 카메라에 local 좌표계를 부여한다고 하자. 이 좌표계는 카메라 공간 또는 시야 공간(view space)을 정의한다. 카메라는 이 view space의 원점에 놓여 양의 z 축을 바라본다. x축은 카메라의 오른쪽 방향이고, y축은 위쪽 방향이다.
카메라 위치에 맞게 물체가 보이도록 하기 위해서는 world상의 모든 물체를 카메라 기준으로 맞춰주어야 한다.

이렇게 world space에서 view space로의 좌표 변경 변환을 시야 변환(view transform)이라 부르고, 해당 변환 행렬을 카메라 변환 행렬 또는 시야 행렬(view matrix)라고 부른다.
이제 이 view matrix를 어떻게 구하는지를 알아보자. 일반적으로 우리가 카메라를 사용한다고 가정해보자. 카메라에 물체가 있을 때 우리가 카메라를 오른쪽으로 이동시키면 카메라 화면에서 물체는 왼쪽으로 이동하는 것처럼 보일 것이다. 또한 카메라를 왼쪽으로 회전시키면 카메라 화면에서 물체는 오른쪽으로 회전하는 것처럼 보일 것이다.
이처럼 카메라의 위치와 방향을 기준으로 world 상의 물체들은 이와 반대로 결정이 된다. 즉 카메라를 world space의 원점으로 옮기고 카메라의 local space를 world space와 일치시키는 것은 카메라를 위한 월드 변환을 반대로 적용하는 것이다. 카메라가 이동하거나 회전할 때마다 카메라 변환 행렬을 새로 만들어야 한다.
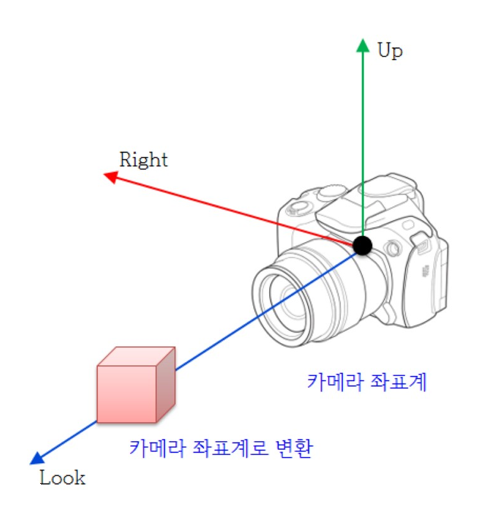
다음은 카메라 변환 행렬을 만드는 함수인 XMMatrixLookAtLH 함수이다. 이 함수가 어떻게 view matrix를 구하는지 자세하게 살펴보도록 하겠다.

우선 행렬을 구하기 위해서는 카메라의 각 축의 방향을 알아야 한다. 방향을 구하기 위해서는 pEye, pAt, pUp이 필요하다. pAt에서 pEye를 벡터로 차를 구한 후 정규화하면 현재 카메라 위치에서 pAt을 바라보는 Look방향벡터를 구할 수가 있다. 그 후 pUp 방향과 Look방향을 외적(cross)하면 서로의 반대 방향인 Right 방향벡터를 구할 수 있게 된다. 외적 한 Right 방향을 이용해 현재 카메라의 Up벡터를 구한다. 그리고 구한 Up, Right, Look 벡터는 각 시야 행렬의 1열, 2열, 3열에 들어간다. 그리고 앞에서도 말했듯이, 물체는 항상 카메라의 반대로 작용되어야 하므로 카메라의 위치 값과 각 카메라의 방향을 곱해주고, 그 결괏값을 반대로(음수의 곱) 해준 다음 각 4행의 1, 2, 3열을 x, y, z로 채워주면 된다. 그러면 다음과 같이 카메라 변환 행렬이 만들어진다.

world상의 한 물체의 각 정점을 view matrix(카메라가 그 물체를 바라본다고 가정했을 때)와 곱해주면 그 물체는 카메라 좌표계를 기준으로 변환되고 카메라에서 보이게 된다.
투영과 동차 절단 공간
지금까지 world space 안의 카메라의 위치와 방향을 설명했다. 그런데 카메라를 서술하는 요소가 하나 더 있다. 바로, 카메라에 보이는 공간이다. 그 공간은 절 두체(frustum)로 정의된다.

모니터에 3차원 장면을 2차원 이미지로 표현하려면 절 두체 안에 있는 3차원 기하구조를 2차원으로 투영(projection) 해야 한다. 투영은 반드시 평행선들이 하나의 소실점으로 수렴하는 방식으로, 그리고 물체의 3차원 깊이가 증가함에 따라 투영의 크기가 감소하는 방식으로 수행해야 한다. 이것을 원근 투영이라고 한다.
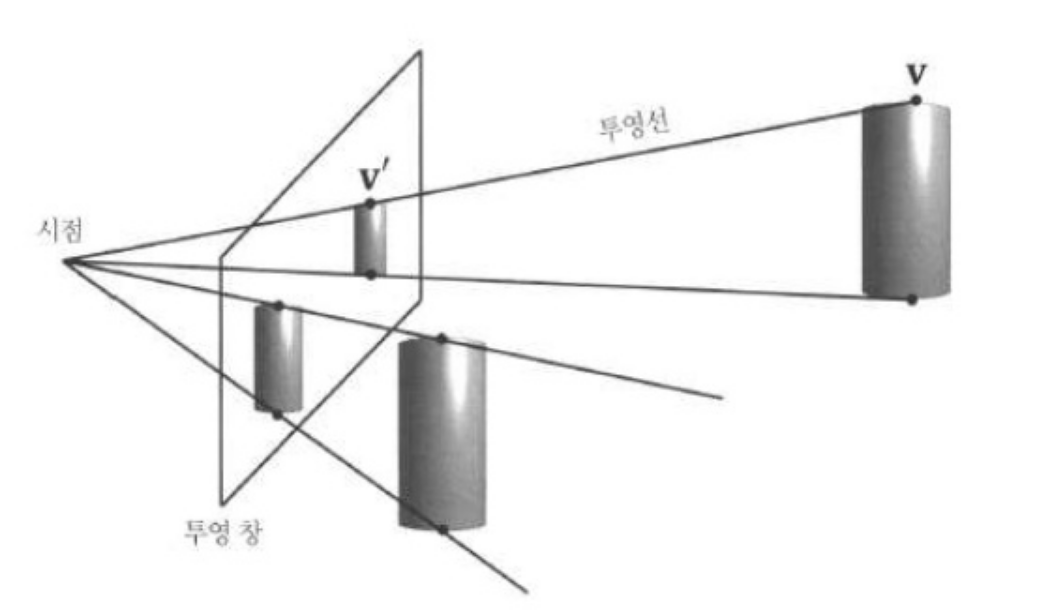
3차원 기하구조의 한 정점에서 시점(eye)으로의 직선을 정점의 투영선이라고 부른다. 원근 투영 변환은 하나의 3차원 정점 v를 그 투영선이 2차원 투영 평면과 만나는 점 v'로 변환하는 것이다. v'을 v의 투영이라고 부른다. 그리고 3차원 물체의 투영은 그 물체를 구성하는 모든 정점의 투영을 뜻한다.
원근 투영(Perspective Projection) 변환 행렬
당연한 얘기지만, 투영을 위해서는 투영 변환 행렬이 필요하다. 투영 변환 행렬은 어떻게 구하는지 알아보자.
우리가 사용하는 모니터는 대부분 정사각형이 아니다. 만약 3차원 world의 정육면체를 투영했다고 가정하고 모니터에 띄우면 다음과 같이 나올 것이다.
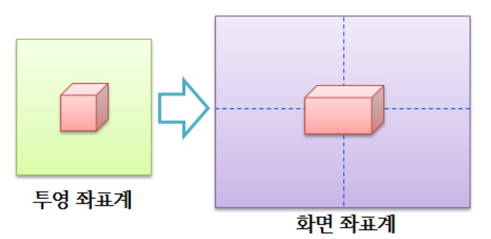
뭔가 잘못되어도 단단히 잘못되었다. 이렇게 변환된다면 우리는 3차원 world를 약간(?) 찌그러 뜨린 듯하게 보게 될 것이다. 그렇기 때문에 투영 변환은 이 점도 같이 고려를 해줘야 한다. 이런 식으로 말이다.

원근 투영 변환은 나누기 연산을 하는 것이다. z값을 기준으로 x, y를 나눈다.(앞의 동차 좌표계에서 w를 나누어 4차원을 3차원으로 만들듯 여기서는 z를 나누어 3차원을 2차원으로 만든다) 하지만 그냥 나누면 위와 같은 문제가 생기므로 먼저 메쉬를 왜곡시켜줘야 한다.
우선 다음과 같은 투영 변환 행렬을 가정한다.
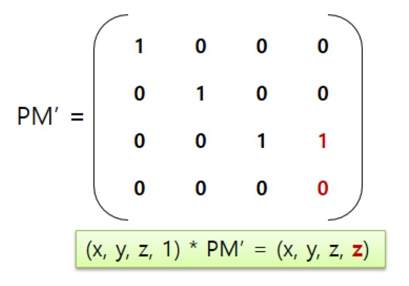
변환된 벡터의 z 요소는 깊이 값(0 ~ 1.0)을 나타낸다. 그리고 w 요소는 w-버퍼나, 깊이 기반 효과 등의 계산에 사용된다. 또 다음과 같은 행렬을 가정하자.

변환된 벡터의 x좌표와 y좌표는 Sx(Scale_x)와 Sy(Scale_y)만큼 크기가 변환된다. Sy가 1보다 크면 FOV(Field Of View, 카메라의 볼 수 있는 시야각)가 좁아지고 1보다 작으면 FOV는 넓어진다.
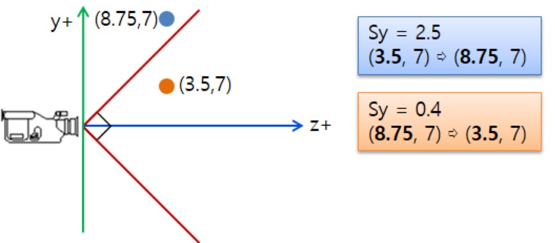
DirectX에서 카메라의 FOV는 항상 90도이다. 그러므로 90도 FOV의 원근 투영 나누기는 그대로 사용한다. 만약에 FOV가 90도가 아니라면 Sx와 Sy를 이용하여 카메라 좌표계에서의 메쉬 크기를 변경한다. 그러면 90도 아닌 FOV효과를 얻을 수 있다. 이 Sx와 Sy는 어떻게 구할까?

왼쪽은 그림을 살펴보자. FOV가 60도 일 때 정점 A는 카메라 절 두체를 벗어났다. FOV 90도로 바꿔도 Sy를 곱한 덕분에 정점은 카메라 시야에서 벗어났다. Sy는 cotan(세타), 즉 1 / tan(세타)이다. 여기서 세타 값은 FOV 각도의 절반이다. 이를 통해 다음과 같이 행렬을 정의할 수 있게 된다.

여기서 모니터 화면 크기의 맞게 해 주기 위해서 추가로 종횡비(Aspect Ratio) 값이 필요하다. 모니터 화면의 가로와 세로를 나눠주면 그것이 바로 종횡비 값이 된다. 640 x 480 해상도 모니터의 종횡비 R은 R = 640 / 480 = 1.333333333...이다. 모니터는 양옆으로 더 긴 직사각형이기 때문에 Sx에 종횡비 값을 나눠준다.

이제 마지막으로 절 두체의 표현 범위를 설정해야 한다. 절 두체는 그 시작이 무조건 카메라의 원점이 아니며 표현 가능한 범위도 무한하지 않다. 절 두체는 다음과 같이 항상 근평면(Near)과 원평면(Far)이 존재한다.

투영이 끝나더라도 z나누기(깊이 버퍼링 알고리즘)를 위해서는 z값(깊이 정보)이 필요하다. 투영된 x, y 성분을 FOV에 맞게 정규화하는 것처럼, 깊이 성분도 일정 구간으로 정규화해야 한다. 이 정규화된 구간은 항상 0부터 1.0까지이다.(0~1.0) 정규화된 z값을 구하기 위해 다음 값들을 변환 행렬에 추가한다.
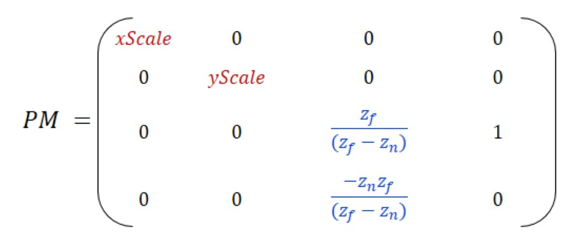
여기서 Zn은 근평면의 거리이고, Zf는 원평면의 거리를 뜻한다. 어떻게 이러한 값들이 나오게 되는 것일까? 이것은 직접 벡터를 이 행렬과 곱한 변환 행렬을 보면 알 수 있다.

변환된 벡터의 z값이 다음과 같이 나왔다. 이제 이 값을 풀어보면 다음과 같이 나온다.
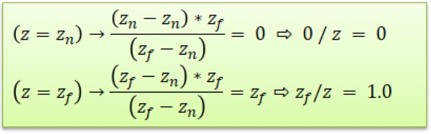
이제 z값이 무엇이냐에 따라서 0 ~ 1.0 범위 안에 들어올 수도 있고, 안 들어 올 수도 있다. 전자의 경우는 절 두체 깊이 범위 안에 있다는 뜻이고, 후자는 범위 밖에 있다는 뜻이다.
투영 변환 행렬은 다음 함수를 통해 구할 수 있다.

이제 이 행렬을 카메라 좌표계에서의 물체의 정점 벡터와 곱하면 FOV 90을 기준으로 하는 카메라 절 두체 범위 내에 있는 정점을 z나누기를 하기 전의 상태로 원근 투영 변환을 한 벡터가 나오게 된다. 이제 z나누기를 하면 최종적으로 정점을 화면에 띄울 위치 (x, y) 값을 도출할 수 있게 된다.
'DirectX > 기초' 카테고리의 다른 글
| [DirectX 12] Direct3D 그리기 연산(정육면체) - 1 (0) | 2020.04.28 |
|---|---|
| [DirectX 12] 렌더링 파이프라인 - 3 (0) | 2020.04.14 |
| [DirectX 12] 렌더링 파이프라인 - 1 (0) | 2020.04.07 |
| [DirectX 12] Direct3D 초기화 - 3 : 시간 측정 (타이머) (0) | 2020.03.23 |
| [DirectX 12] Direct3D 초기화 - 2 (0) | 2020.03.12 |


