
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- 디자인패턴
- 멀티프로세서
- 알고리즘
- 자료구조
- I/O장치
- 파일시스템 구현
- DirectX12
- 병행성 관련 오류
- Direct12
- codility
- 타입 객체
- 멀티쓰레드
- 컨디션 변수
- 렌더링 파이프라인
- 다이나믹프로그래밍
- 다이나믹 프로그래밍
- 병행성
- 락
- OS
- 그리디알고리즘
- 운영체제
- DirectX 12
- 백준
- 프로그래머스
- 쓰레드
- 동적계획법
- directx
- 영속성
- 스케줄링
- 그리디 알고리즘
- Today
- Total
기록공간
3-4장. 락(Lock) - 3 본문
Fetch-And-Add
마지막 하드웨어 기반의 기법은 Fetch-And-Add 명령어로 원자적으로 특정 주소의 예전 값을 반환하면서 값을 증가시킨다. C, C++ 코드로 표현하면 다음과 같다.
// C
int FetchAndAdd(int *ptr)
{
int old = *ptr;
*ptr = old + 1;
return old;
}// C++
#include <atomic>
int FetchAndAdd(std::atomic_int &ptr)
{
return ptr++;
}C++ 코드를 보면 atomic_int이 보일 것이다. 이건 무엇일까? C++11부터 지원하는 Atomic 자료구조이다. 이것은 기본 자료 구조의 일부를 원자적으로 구현해놓은 것이다.(char, int, short, bool) Atomic 자료구조를 사용하기 위해서는 <atomic> 라이브러리를 추가해야 한다. Atomic 자료구조는 읽기와 쓰기, 각종 연산(+=, -=, ++, --)을 원자적으로 수행한다.
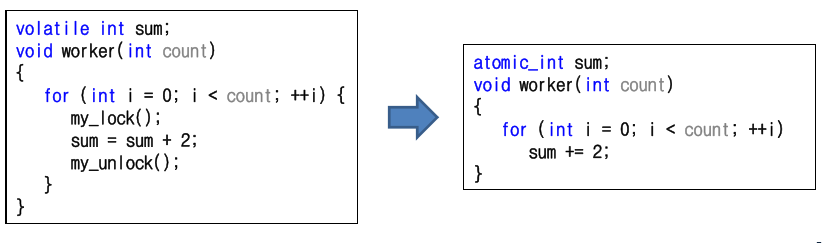
티켓 락
위 키워드를 사용하여 티켓 락이라는 것을 만들어 보자.
class mutex
{
atomic_int ticket;
atomic_int turn;
public:
mutex()
{
ticket = 0;
turn = 0;
}
void lock()
{
int myturn = ticket++;
while(turn != myturn); // 스핀
}
void unlock()
{
turn++;
}
}하나의 쓰레드가 락 획득을 원하면, int형 Atomic 자료구조인 티켓 변수가 원자적으로 값을 증가(++)시킨다. 결과 값은 해당 쓰레드의 "차례(turn)"를 나타낸다. 만약 한 쓰레드가 (turn == myturn)이라는 조건에 부합하면 그 쓰레드가 임계 영역에 진입할 차례인 것이다. 언락 동작은 차례 변수의 값을 증가시켜서 대기 중인 다음 쓰레드에게 임계 영역 진입 차례를 넘겨준다.
티켓 락은 티켓과 차례 조합을 사용하여 락을 만든다. 때문에 락을 쓰레드 각자의 순서에 따라 진행한다. 이는 스핀락 평가 기준 중 하나인 공정성을 만족시킨다. 이전 까지의 기법들은 이러한 보장이 없었다. 예를 들어 Test-And-Set 같은 경우에는 lock(), unlock()을 하더라도 어떤 쓰레드는 계속 회전만 하고 있을 수 있다.
과도한 스핀
이제까지 소개한 하드웨어 기반의 락은 간단하고, 확실히 동작한다. 이것은 큰 장점이다. 하지만 때로는 이러한 해법이 효율적이지 않은 경우도 있다.
두 개의 쓰레드를 프로세서가 하나인 시스템에서 실행한다고 해 보자. 쓰레드 0이 임계 영역 내에 있어 락을 보유한 상태에서 인터럽트에 걸렸다고 해 보자. 쓰레드 1이 락을 획득하려고 시도하는데, 누군가 이미 갖고 있는 것을 알았다. 그래서 락을 대기하며 스핀하기 시작한다. 스핀하다가, 타이머 인터럽트에 의해 쓰레드 0이 다시 실행하게 되고 락을 해제한다. 마지막으로 쓰레드 1이 다시 실행하게 되면 그렇게 많이 스핀하지 않아도 락을 획득할 수 있게 된다. 쓰레드는 스핀 구문을 실행하며 변경되지 않을 값을 변경되기 기다리며 시간만 낭비한다.(즉 전체 타임슬라이스를 락의 상태를 검사하는 데에 낭비한다.) 이러한 현상을 호위현상(Convoying)이라고 한다. N개의 쓰레드가 하나의 락을 획득하기 위해 경쟁하면 더 심각해진다. 그렇다면 이렇게 과도한 회전을 피하는 방법은 무엇이 있을까?
하지만 하드웨어의 지원으로만 이 문제를 해결할 수 없다. 운영체제로부터의 지원이 추가로 필요하다. 어떻게 하면 이 문제를 해결할 수 있을까?
간단한 해결 : 양보
첫 번째 시도는 단순한 방법이다. 락이 해제되기를 기다리며 스핀해야 하는 경우 자신에게 할당된 CPU를 다른 쓰레드에 양보하는 것이다. 다음 코드를 한번 보자.
class mutex
{
public:
mutex()
{
flag = false;
}
void lock()
{
while(!atomic_compare_exchange_strong(&flag, flase, true))
std::this_thread::yield(); // CPU를 양보한다.
}
void unlock()
{
flag = false;
}
};하나의 쓰레드는 실행 중(running), 준비(ready), 막힘(blocked)이라는 세 가지 상태가 있다. OS에서 제공하는 yield() 메서드는 쓰레드를 실행 상태에서 준비 상태로 변환하여 다른 쓰레드가 실행 중 상태로 전이하도록 한다. 결과적으로 양보 동작은 스케줄 대상에서 자신을 빼는 것(dischedule)이나 마찬가지이다.
하지만 이 기법은 라운드 로빈 스케줄러 특성상 쓰레드 수가 많은 경우 실행하고 양보하는 패턴이 자주 등장하게 되는데, 이는 문맥 교환에 대한 비용이 상당히 증가하게 된다는 것을 뜻한다. 더 안 좋은 것은 굶주림 문제는 여전히 존재한다는 것이다. 나머지 쓰레드들은 임계 영역에 반복적인 출입을 하는데, 어떤 쓰레드는 무한히 양보만 하고 있을 수 있다. 이 문제를 직접적으로 다루는 해법이 필요하다.
큐의 사용 : 스핀 대신 잠자기
이전 방법들의 근본적인 문제는 너무 많은 부분을 운에 맡긴다는 것이다. 어떤 선택이 되었든 낭비의 여지가 있고, 굶주림 상태를 막지 못한다.
어떤 스레드가 다음으로 락을 획득할지를 명시적으로 제어할 수 있어야 한다. 이를 위해서 큐를 사용한다. 큐를 사용하여 누가 락을 기다리고 있는지를 기록한다. 또한 OS에서 두 개의 호출 문이 있는데, park()는 호출하는 쓰레드를 잠재우는 함수이고, unpark(threadID)는 threadID로 명시된 특정 쓰레드를 깨우는 함수이다. 이 두 루틴은 이미 사용 중인 락을 요청하는 프로세스를 재우고 해당 락이 해제되면 깨우도록 하는 락을 제작하는 데 앞뒤로 사용할 수 있다.
class mutex
{
atomic_bool flag;
atomic_bool guard;
queue<std::thread::id> q;
public:
mutex() {flag = false; guard = false;}
void lock()
{
while(atomic_compare_exchange_strong(&guard, false, true))
; // 회전하면서 가드락을 획득한다.
if(flag == false)
{
flag = true; // 락 획득
guard = false;
}
else
{
// 이미 다른 쓰레드가 락을 획득하였다면
p.push(std::this_thread::get_id());
guard = false;
park();
}
}
void unlock()
{
while(!atomic_compare_exchange_strong(&guard, false, true))
;
if(q.empty())
flag = false; // 락을 포기한다.(누구도 락을 원치 않음)
else
// 자고 있는 쓰레드 중 가장 먼저 실행될 쓰레드의 락을 획득함 (다음 쓰레드를 위해)
unpark(q.top());
}
}guard 변수는 flag와 큐의 삽입 삭제 동작을 스핀 락으로 보호하는 데 사용한다. 즉 이 방법은 회전 대기를 완벽하게 배제하지는 못한다. 락을 획득하거나 해제하는 과정에서 인터럽트에 걸릴 수 있다. 그 과정에서 다른 쓰레드는 락의 해제를 기다리며 회전 대기하게 된다. 하지만 대기 시간은 꽤 짧다. 임계 영역에 진입하는 것이 아니라 락과 언락 코드 내의 몇 개의 명령어만 수행하면 되기 때문이다. 그렇기 때문에 이 접근법은 합리적이다.
깨우기 / 대기 경쟁
만약 thread B가 park()를 호출하기 바로 전에 thread A가 락을 반납하면 어떻게 될까? 그렇게 되면 thread B는 영원히 대기상태에 빠지게 된다. 이를 깨우기 / 대기 경쟁 문제라고 한다.
Solaris에서는 이 문제를 세번째 시스템 콜인 setpark()를 사용하여 해결한다. setpark()를 호출하면 그 호출한 쓰레드는 곧 park할 것임을 미리 알려준다. 만약 위의 경우처럼 인터럽트가 발생하여 다른 쓰레드가 그 사이에 unpark를 호출했다면, park 호출은 쓰레드를 재우지 않고 즉시 리턴시킨다.
p.push(std::this_thread::get_id());
setpark(); // 추가
guard = false;
park();
Futex
다른 운영체제들도 유사한 기능을 지원하지만 세부적인 내용은 다르다.
Linux의 경우 futex라는 것을 지원한다. Solaris의 park(), unpark()와 비슷하지만, 각 futex는 특정 물리 메모리 주소와 연결이 되어 있으며 futex마다 커널 내부의 큐를 갖고 있다. 호출자는 futex를 호출하여 필요에 따라 잠을 자거나 깨어날 수 있다.
futex에는 두 개의 명령어가 제공된다. futex_wait(address, expected) 명령어는 address 값과 expected 값이 동일한 경우 쓰레드를 잠재운다. 같지 않다면 즉시 리턴한다. futex_wake(address) 명령어를 호출하면 큐에서 대기하고 있는 쓰레드 하나를 깨운다.(준비 상태로 바꾼다)
다음은 nptl 라이브러리 lowlevellock.h에서 발췌한 코드이다.
void mutex_lock(int *mutex)
{
int v;
if(atomic_bit_test_set(mutex, 31) == 0)
return;
atomic_increment(mutex);
while(1)
{
if(atomic_bit_test_set(mutex, 31) == 0)
{
atomic_decrement(mutex);
return;
}
v = *mutex;
if(v >= 0)
continue;
futex_wait(mutex, v);
}
}
void mutex_unlock(int *mutex)
{
if(atomic_add_zero(mutex, 0x80000000))
return;
futex_wake(mutex);
}이 코드에서는 하나의 정수(0x80000000)를 이용하여 락의 사용 중 여부와(최상위 비트를 사용하여), 대기자 수를 표현한다.(나머지 비트를 사용하여) 최상위 비트는 부호를 나타내기 때문에, 만약 락이 음수라면 락이 사용 중인 것을 나타낸다. 이 코드는 일반적인 경우에 대한 최적화 방법을 제시한다. 단 하나의 쓰레드가 락을 획득하고 해제하는 경우라면 아주 약간만 일을 하도록 하였다. (비트 단위의 TestAndSet으로 락을 획득하고 원자적 덧셈을 하여 락을 해제한다)
2단계 락
2단계 락(2-phase-locking) 기법은 락이 곧 해제될 것 같은 경우라면 회전 대기가 유용할 수 있다는 것에서 착안하였다. 첫 번째 단계는 곧 락을 획득할 수 있을 것이라는 기대로 회전하며 기다린다. 만약 첫 회전에서 락을 획득하지 못하였다면 두 번째 단계로 진입하여 호출한 쓰레드를 재우고 락이 해제된 후에 깨어나도록 한다. 앞서 살펴본 Linux의 락은 같은 형태를 가지는 락이지만 한 번만 회전한다. 일반적인 방법은 futex가 잠재우기 전에 일정 시간 동안 반복문 내에서 회전하도록 하는 것이다.
2단계 락은 하이브리드 방식의 일종이다. 이 기법이 무조건 좋다는 것은 확실하지 않다. 왜냐하면 컴퓨터 하드웨어 환경과 작업량 같은 것에 많은 것을 의존하기 때문이다. 항상 그렇듯, 모든 경우에 잘 동작하는 범용적인 락을 만드는 것은 상당히 어려운 일이다.
'OS' 카테고리의 다른 글
| 3-6장. 컨디션 변수 (0) | 2020.05.01 |
|---|---|
| 3-5장. 락 기반 병렬 자료 구조 (0) | 2020.04.29 |
| 3-3장. 락(Lock) - 2 (0) | 2020.04.24 |
| 3-2장. 락(Lock) - 1 (0) | 2020.04.22 |
| 3-1장. 쓰레드 API (0) | 2020.04.13 |


