
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- 컨디션 변수
- 파일시스템 구현
- 타입 객체
- 백준
- 디자인패턴
- Direct12
- 영속성
- 병행성 관련 오류
- codility
- directx
- 동적계획법
- I/O장치
- 운영체제
- 자료구조
- 스케줄링
- 쓰레드
- 다이나믹 프로그래밍
- 그리디 알고리즘
- 프로그래머스
- 멀티쓰레드
- 병행성
- 멀티프로세서
- 알고리즘
- 락
- 렌더링 파이프라인
- OS
- 다이나믹프로그래밍
- DirectX 12
- DirectX12
- 그리디알고리즘
- Today
- Total
기록공간
2-8장. 주소 변환의 원리 본문
효율적인 메모리 가상화
우리는 앞에서, CPU 가상화를 위한 제한적 직접 실행(LDE)에 대해서 자세하게 살펴봤다.
https://lipcoder.tistory.com/55?category=834992
2-2장. Mechanism : 제한적 직접 실행 원리
CPU를 가상화하기 위해서 운영체제는 여러 작업들이 동시에 실행되는 것처럼 보이도록 물리적인 CPU를 공유한다. 한 프로세스를 잠시 동안 실행하고 다른 프로세스를 또 잠깐 실행하고, 이런 식으로 계속해서 잠깐..
lipcoder.tistory.com
메모리 가상화에서도 비슷한 전략을 추구할 것이다. 가상화를 제공하는 동시에 효율성(Efficiency)과 제어(Control) 모두를 추구한다.
효율성을 높이려면 하드웨어 지원을 활용할 수밖에 없다. 처음에는 몇 개의 레지스터만 사용하는 정도부터 TLB, 페이지 테이블 등으로 점차 복잡한 하드웨어를 사용하게 될 것이다.
제어는 응용 프로그램이 자기자신의 메모리 이외에는 다른 메모리에 접근하지 못한다는 것을 운영체제가 보장하는 것을 의미한다. 프로그램을 다른 프로그램으로부터 보호하고 운영체제를 프로그램으로부터 보호하기 위하여 하드웨어의 도움이 필요하다.
주소 변환
우리가 다룰 기법은 하드웨어-기반 주소 변환(Hardware-based address translation) 또는 짧게 주소 변환(Address translation)이다. 이 기술은 제한적 직접 실행 방식에 부가적으로 사용되는 기능이라고 생각할 수 있다. 주소 변환을 통해 하드웨어는 명령어 반입, 탑재, 저장 등의 가상 주소를 정보가 실제 존재하는 물리 주소로 변환한다. 프로그램의 모든 메모리 참조를 실제 메모리 위치로 재지정하기 위하여 하드웨어가 주소를 변환한다.
하지만 하드웨어만으로는 메모리 가상화를 구현할 수 없다. 정확한 변환이 일어날 수 있도록 하드웨어를 셋업하기 위해 운영체제가 관여해야 한다. 즉, 운영체제는 하드웨어에게 어떻게 변환할 것인지를 알려주어야 한다. 운영체제는 메모리의 빈 공간과 사용 중인 공간을 항상 알고 있어야 하고, 메모리 사용을 제어하고 관리한다.
이 모든 작업의 목표는 다음과 같다. 프로그램이 자신의 전용 메모리를 소유하고 그안에 자신의 코드와 데이터가 있다는 환상을 만드는 것이다.
주소 변환의 예
주소 변환 구현을 위해 어떤 것이 필요한지, 왜 그런 기법이 필요한지 알기위해 간단한 예를 살펴보자. 다음 C언어 코드를 보자.

함수 안에 정수형 지역변수 x를 선언하고 x에 3을 더하는 코드이다. 여기서 우리가 검토하고자 하는 코드는 메모리에서 값을 탑재하고, 3을 증가시키고, 다시 메모리를 저장하는 짧은 코드이다.(x = x + 3)
컴파일러는 이 코드를 어셈블리 코드로 변환하는데 그 결과는 다음과 같다.

이 코드는 비교적 이해하기 쉽다. x의 주소는 레지스터 ebx에 저장되어 있다고 가정하고 이 주소에 저장되어 있는 값을 mov 명령어를 사용하여 범용 레지스터 eax에 넣는다. 다음 명령은 3을 더하고, 마지막 명령은 eax의 같을 같은 위치의 메모리에 저장한다.

위 그림에서 코드와 데이터가 프로세스 주소 공간에 어떻게 배치되어 있는지 볼 수 있다. 세 개 명령어 코드는 주소 128에 위치하고, 변수 x의 값은 주소 15KB에 위치한다. 그림에서 x의 초기 값은 3000이다.
이 명령어가 실행되면 프로세스 관점에서 다음과 같은 메모리 접근이 일어난다.
-
주소 128의 명령어를 반입
-
명령어 실행 (15KB 주소에서 복사)
-
주소 132의 명령어 반입
-
명령어 실행 (메모리 접근 없음)
-
주소 135의 명령어 반입
-
명령어 실행 (15KB 주소에 복사)
총 5번의 메모리 접근이 있게 된다.
주소 공간 재배치
위 그림을 토대로 프로그램 관점에서 주소 공간은 주소 0부터 시작하여 최대 16KB까지이다. 프로그램이 생성하는 모든 메모리 참조는 이 범위 내에 있어야 한다. 메모리 가상화를 위해 운영체제는 프로세스를 물리 메모리 주소 0이 아닌 다른 곳에 위치시키고 싶다. 하지만 컴파일러는 0번 주소에 프로그램을 위치시킨다.(실제 위치를 알 수 없으므로, 컴퓨터마다 OS 버전마다 메모리 크기, 위치가 다르다) 어떻게 하면 프로세스 모르게 메모리를 다른 위치에 재배치하느냐가 지금부터 해결해야 할 문제이다. 주소 0번지부터 시작하는 가상 주소 공간의 환상을 어떻게 제공할 수 있을까?

동적(하드웨어-기반) 재배치
하드웨어 기반 주소 변환을 이해하기 위하여 먼저 첫 번째 실현 사례를 설명한다. 첫 번째 시분할 컴퓨터에서 베이스와 바운드(Base and bound)라는 간단한 아이디어가 채택되었다. 이 기술은 또한 동적 재배치(Dynamic relocation)라고 한다.
각 CPU마다 2개의 하드웨어 레지스터가 필요하다. 하나는 베이스(Base) 레지스터라고 불리고, 다른 하나는 바운드(Bound) 레지스터 혹은 한계(Limit) 레지스터라고 불린다. 이 베이스와 바운드 쌍은 우리가 원하는 위치에 주소 공간을 배치할 수 있게 한다. 배치와 동시에 프로세스가 오직 자신의 주소 공간에만 접근한다는 것을 보장한다.
각 프로그램이 주소 0에 탑재되는 것처럼 작성되고 컴파일된다. 프로그램 시작 시, 운영체제가 프로그램이 탑재될 물리 메모리 위치를 결정하고 베이스 레지스터를 그 주소로 지정한다. 위 그림에서는 운영체제는 프로세스를 물리 주소 32KB에 저장하기로 결정하고 베이스 레지스터를 이 값으로 설정한다.
프로세스가 실행되면서 재미있는 일이 발생한다. 프로세스에 의해 생성되는 모든 주소가 다음과 같은 방법으로 프로세서에 의해 변환된다.

프로세스가 생성하는 메모리 참조는 가상 주소이다. 하드웨어는 베이스 레지스터의 내용을 이 주소에 더하여 물리 주소를 생성한다.
이를 이해하기 위해 명령어가 실행될 때 무슨 일이 벌어지는지 추적해 보자. 예전 코드 중 하나를 살펴보자.

프로그램 카운터(PC)는 128로 설정된다. 하드웨어가 이 명령어를 반입할 때, 먼저 PC 값을 베이스 레지스터의 값 32KB(32768)에 더해 32896의 물리 주소를 얻는다. 그런 후 하드웨어는 해당 물리 주소에서 명령어를 가져온다. 그리고 프로세서는 명령어의 실행을 시작한다. 얼마 후 프로세스는 가상 주소 15KB(x가 저장된 위치)의 값을 탑재하라는 명령을 내린다. 이 주소를 프로세서가 받아 다시 베이스 레지스터(32KB)를 더하고 물리 주소 47KB에서 원하는 내용을 탑재한다.
가상 주소에서 물리 주소로의 변환이 주소 변환이라고 부르는 바로 그 기술이다. 하드웨어는 프로세스가 참조하는 가상 주소를 받아들여 데이터가 실제로 존재하는 물리 주소로 변환한다. 이 주소의 재배치는 실행 시에 일어나고, 프로세스가 실행을 시작한 이후에도 주소 공간을 이동할 수 있기 때문에, 동적 재배치라고도 불린다.
바운드 레지스터는 보호를 위해 존재한다. 프로세서는 먼저 메모리 참조가 합법적인가를 확인하기 위해 가상 주소가 바운드(경계) 안에 있는지 확인한다. 앞에서 다른 간단한 예에서, 바운드 레지스터는 항상 16KB로 설정한다. 프로세스가 바운드보다 큰 가상 주소 또는 음수인 가상 주소를 참조하면 CPU는 예외를 발생시키고 프로세스는 종료될 것이다. 바운드의 요점은 프로세스가 생성한 모든 주소가 합법적이고 프로세스의 "범위"에 있다는 것을 확인하는 것이다.

OS에서의 메모리 가상화
앞서 살펴본 동적 재배치에서 운영체제가 할 일은 무엇이 있는지 살펴보겠다. 운영체제는 여기서 3가지 중요한 역할을 한다.
-
프로세스가 시작할 때 : 물리 메모리에서 필요한 공간 찾기
-
프로세스가 종료할 때 : 다음 사용자를 위해 메모리 회수
-
문맥 교환이 일어날 때 : 베이스와 바운드 레지스터 값 저장, PCB의 저장, 프로세스의 위치 변경 가능(프로세스 메모리 전체 복사 필요)
하나씩 세세하게 살펴보도록 하겠다.
OS측면 : 프로세스가 시작할 때
프로세스가 생성될 때 운영체제는 주소 공간이 저장될 메모리 공간을 찾아 조치를 취해야 한다. 운영체제는 프물리 메모리를 슬롯의 배열로 보고 각 슬롯의 사용 여부를 관리한다. 새로운 프로세스가 생성되면 운영체제는 새로운 주소 공간 할당에 필요한 영역을 찾기 위해 흔히 빈 공간 리스트(Free list)라고 불리는 자료 구조를 검색해야 한다. 검색을 통해 선택된 공간을 사용중이라고 표시한다.

위 그림을 살펴보면 물리 메모리 슬롯의 배열에서 첫번째 슬롯을 운영체제 자신이 사용하고 있다. 그리고 운영체제는 프로세스의 위치를 물리 주소 32KB에서 시작하는 슬롯으로 재배치한 것을 볼 수 있다. 다른 두 슬롯(16~32KB, 48~64KB)은 비어 있다. 따라서 빈 공간 리스트는 이 두 항목으로 구성된다.
OS측면 : 프로세스가 종료할 때
프로세스가 종료할 때, 즉 정상적으로 종료될 때 또는 잘못된 행동을 하여 강제적으로 죽게 될 때 프로세스가 사용하던 메모리를 회수하여 다른 프로세스나 운영체제가 사용할 수 있게 해야 한다. 프로세스가 종료하면, 운영체제는 종료한 프로세스의 메모리를 다시 빈 공간 리스트에 넣고 연관된 자료 구조를 모두 정리한다.
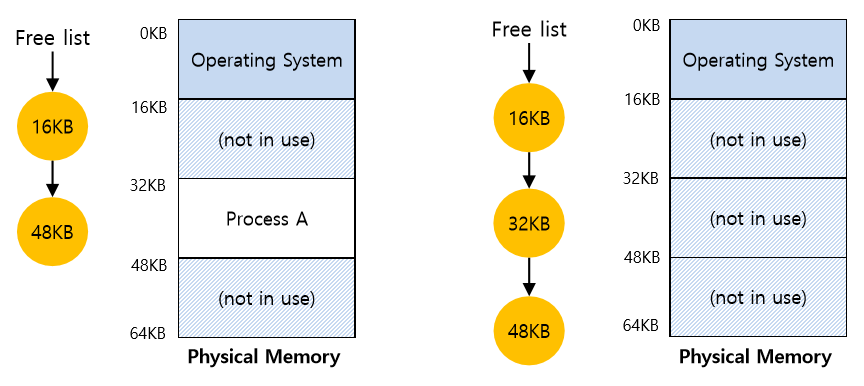
OS측면 : 문맥교환 발생 시
운영체제는 문맥 교환이 일어날 때에도 몇 가지 추가 조치를 취해야 한다. CPU마다 한 쌍의 베이스-바운드 레지스터만 존재하고 각 프로그램은 다른 물리 주소에 탑재되어야 하기 때문에 실행 중인 프로그램마다 다른 값을 가진다. 운영체제는 프로세스 전환 시 베이스와 바운드 쌍을 저장하고 복원해야 한다. 운영체제가 실행 중인 프로세스를 중단시키기로 결정하면 운영체제는 메모리에 존재하는 프로세스 별 자료구조 안에 베이스와 바운드 레지스터의 값을 저장해야 한다. 이 자료 구조는 프로세스 구조체(Process structure) 또는 프로세스 제어 블럭(Process Control Block, PCB)이라고 불린다. 마찬가지로 운영체제는 실행 중인 프로세스를 다시 시작할 때 또는 처음 실행시킬 때, 이 프로세스에 맞는 값으로 CPU의 베이스와 바운드 값을 설정해야 한다.
프로세스가 중단되면 (실행상태가 아닌 경우), 운영체제가 메모리의 현 위치에서 다른 위치로 주소 공간을 비교적 쉽게 옮길 수 있다는 사실에 주목하자. 프로세스의 주소 공간을 이동시키려면 운영체제는 먼저 프로세스의 실행을 중지시킨다. 그런 후 운영체제는 현재 위치에서 새 위치로 주소 공간을 복사한다. 마지막으로, 운영체제는 PCB에 저장된 베이스 레지스터를 갱신하여 새 위치를 가리키도록 한다. 프로세스가 실행을 재개하면 새로운 베이스 레지스터가 복원되고 다시 실행을 시작하고, 명령어와 데이터가 전혀 다른 새 위치에 존재한다는 사실을 인식하지 못한다.

베이스와 바운드의 문제
동적 재배치는 비효율적이다. 예를 들어, 재배치된 프로세스는 32KB에서 48KB까지의 물리 메모리를 사용한다. (위 예시에서) 그러나 프로세스 스택과 힙이 아주 크지 않기 때문에, 둘 사이의 공간이 낭비되고 있다. 할당된 영역의 내부 공간이 사용되지 않기 때문에, 즉 단편화가 발생되어 낭비된다.
이런 유형의 낭비를 내부 단편화(Internal fragmentation)라고 한다. 현재 접근 방식에서 비록 더 많은 프로세스를 탑재할 수 있는 충분한 물리 메모리가 있더라도, 고정 크기의 슬롯에 주소 공간을 배치해야 하기 때문에 내부 단편화가 발생한다. 물리 메모리의 이용률을 높이고 내부 단편화를 방지하기 위해 더 정교한 기법이 필요하다.
'OS' 카테고리의 다른 글
| 2-10장. 빈 공간 관리(메모리) (0) | 2020.03.18 |
|---|---|
| 2-9장. 세그멘테이션 (0) | 2020.03.13 |
| 2-7장. 메모리 관리 API (0) | 2020.03.04 |
| 2-6장. 주소 공간의 개념 (0) | 2020.03.02 |
| 2-5장. 멀티프로세서 스케줄링 (2) | 2020.02.28 |



