
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- OS
- 병행성
- I/O장치
- 멀티쓰레드
- 파일시스템 구현
- DirectX 12
- 운영체제
- Direct12
- directx
- 렌더링 파이프라인
- 멀티프로세서
- DirectX12
- 다이나믹프로그래밍
- codility
- 그리디 알고리즘
- 알고리즘
- 스케줄링
- 자료구조
- 디자인패턴
- 프로그래머스
- 타입 객체
- 백준
- 영속성
- 컨디션 변수
- 쓰레드
- 락
- 동적계획법
- 병행성 관련 오류
- 그리디알고리즘
- 다이나믹 프로그래밍
- Today
- Total
기록공간
다익스트라 알고리즘 본문
개요
다익스트라(Dijkstra) 알고리즘은 다이나믹 프로그래밍을 활용한 대표적인 최단 경로(short path)탐색 알고리즘이다. 보통 인공위성 GPS 소프트웨어 등에 사용된다.
다익스트라 알고리즘은 특정한 하나의 정점에서 다른 모든 정점으로 가는 최단 경로를 알려준다. 하지만 주의할 점이 있는데 음의 간선은 포함할 수 없다는 점이다. 물론 현실 세계에서는 음의 간선이 존재하지 않기 때문에 다익스트라 알고리즘은 현실 세계에 사용하기에 매우 적합한 알고리즘 중 하나이다.
다익스트라 알고리즘이 다이나믹 프로그래밍 문제인 이유는 최단 거리는 여러 개로 이루어져 있기 때문이다. 그렇기 때문에 작은 문제가 큰 문제의 부분 집합에 속해 있다고 볼 수 있다. 기본적으로 다익스트라는 하나의 최단 거리를 구할 때 그 이전까지 구했던 최단 거리 정보를 그대로 사용한다는 특징이 있다. 이는 다이나믹 프로그래밍의 특징이기도 하다.
과정
다음의 경우를 고려해보자. 1부터 다른 모든 노드로 가는 최단 경로를 구해야 한다.

기본적으로 다음과 같이 1과 붙어있는 노드인 2, 3, 4까지의 최단 거리를 각각 3, 6, 7로 산정할 수 있다. 컴퓨터는 당장 하나씩밖에 계산하지 못한다. 예를 들면 현재 상황에서 1 -> 3으로 가는 최소 비용은 6이다.
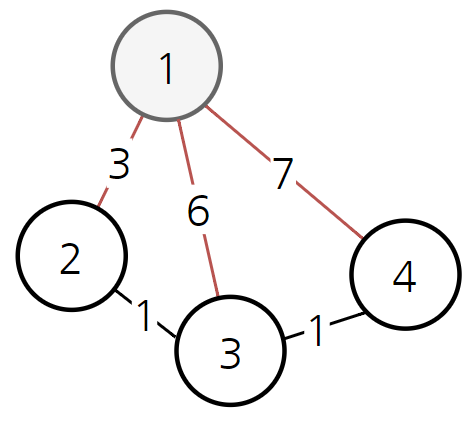
이후 다음과 같이 노드 2를 처리하게 되었다고 가정해보자.

처리하는 과정에서 컴퓨터는 경로 1 -> 3의 비용이 6인데에 반해 경로 1 -> 2 ->3 이 총비용 3 + 1 = 4로 더 저렴하다는 것을 알게 된다. 이 때 현재까지 알고 있던 3으로 가는 최소 비용 6을 새롭게 4로 갱신한다. 다시 말해 다익스트라 알고리즘은 현재까지 알고 있던 최단 경로를 계속해서 갱신한다.
구체적인 작동 과정은 다음과 같다.
-
출발 노드를 설정한다.
-
출발 노드를 기준으로 각 노드의 최소 비용을 저장한다.
-
방문하지 않은 노드 중에서 가장 비용이 적은 노드를 선택한다.
-
해당 노드를 거쳐 특정한 노드로 가는 경우를 고려하여 최소 비용을 갱신한다.
-
3 ~ 4번 과정을 반복한다.

위와 같이 그래프가 준비되어 있다고 가정하자. 이러한 그래프는 컴퓨터 안에서 처리할 때 이차원 배열 형태로 처리할 수 있다. 아래 표와 같이 해준다. 아래 표의 값은 특정 행에서 열로 가는 비용을 뜻한다. 예를 들어 1행 3열의 값이 5이다. 이것은 1 -> 3으로 가는 비용이 5라는 것이다.

가는 길이 존재하지 않는 경우를 구분하기 위해 무한 값을 넣었다. 또한 자기자신을 가는 비용은 없으므로 0 값을 넣어주었다.
이제 이 상태에서 1번 노드를 선택해보자.

노드 1을 선택한 상태에서, 그것과 연결된 세 개의 간선을 확인한 상태이다. 1번 노드에서 다른 정점으로 가는 최소 비용은 아래 표와 같다.

배열을 만든 뒤에 이 최소 비용 배열을 계속해서 갱신할 것이다. 현재 방문하지 않은 노드 중 가장 비용이 적은 노드는 1 -> 4로 가는 방법이다. 따라서 다음 검사할 노드로 4번 노드를 선택한다. 4번 노드를 거쳐서 가는 경우를 모두 고려하여 최소 비용 배열을 갱신하면 된다.

기존에 1 -> 5로 가는 최소 비용은 무한이였다. 하지만 4를 거치면서 1 -> 4 -> 5로 갈 수 있게 되면서 1 + 1 = 2로 최소 비용 배열을 갱신해준다. 또한 1 -> 4 -> 3으로 가는 경우는 비용이 1 + 3 = 4이므로 기존의 비용 5보다 더 저렴하다. 따라서 최소 비용 배열을 갱신해준다. 결과적으로 아래 표와 같다.

이제 다음으로 방문하지 않은 노드 중에서 가장 비용이 적은 노드는 2번 노드이다.

다음과 같이 노드 2를 거쳐 가더라도 비용이 갱신되는 경우가 없을 수 있다. 그렇기 때문에 배열은 그대로 유지된다.

다음 방문하지 않은 노드 중 가장 비용이 적은 노드는 5번째 노드이다.

위와 같이 1 -> 4 -> 5 -> 3으로 가는 경우 경로의 비용은 1 + 1 + 1 = 3이므로 기존의 4보다 더 저렴하다. 따라서 노드 3으로 가는 비용을 3으로 갱신한다. 1 -> 4 -> 5 -> 6으로 가는 경우 경로의 비용이 1 + 1 + 2 = 4로 기존의 무한보다 더 저렴하다. 따라서 노드 6으로 가는 비용을 4로 갱신한다.

이후에 방문하지 않은 노드 중 가장 저렴한 노드 3을 방문한다. 하지만 최소 비용 갱신이 일어나지 않는다.
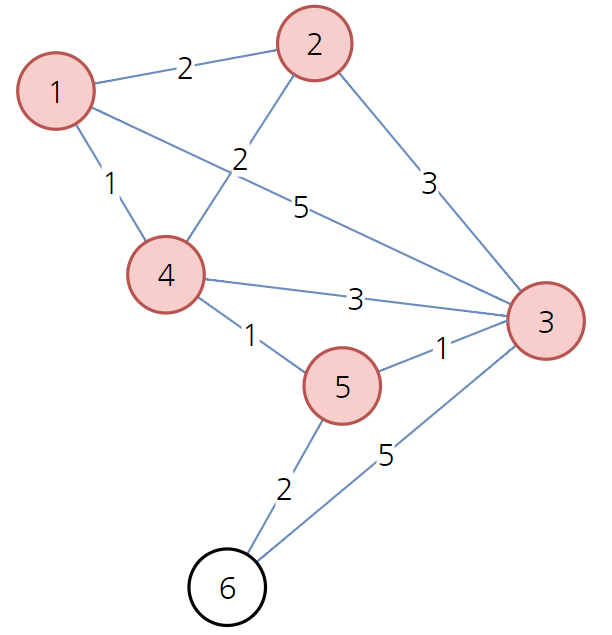

이제 마지막 남은 노드 6을 살펴보자.

노드 6을 방문한 뒤에도 결과는 같다. 따라서 최종 배열은 다음과 같이 형성된다.

구현
O(N^2) 방법
코드로 구현하면 다음과 같다.
#include <iostream>
#include <vector>
using namespace std;
int number = 6;
int INFINITE = 1000000000;
vector<vector<int>> info
{
{0, 2, 5, 1, INFINITE, INFINITE},
{2, 0, 3, 2, INFINITE, INFINITE},
{5, 3, 0, 3, 1, 5},
{1, 2, 3, 0, 1, INFINITE},
{INFINITE, INFINITE, 1, 1, 0, 2},
{INFINITE, INFINITE, 5, INFINITE, 2, 0}
};
vector<bool> visited(6, false); // 방문 표시를 위한 컨테이너
vector<int> dist(6, INFINITE); // 각 노드로 가는 최소비용을 담는 컨테이너
// 아직 방문하지 않은 정점 중
// 가장 최소 거리를 가지는 정점을 반환
int GetSmallIndex()
{
int min = INFINITE;
int index = 0;
for (int i = 0; i < number; ++i)
{
if (dist[i] < min && !visited[i])
{
min = dist[i];
index = i;
}
}
return index;
}
// 다익스트라 알고리즘 수행
void Dijkstra(int start)
{
// start에서 가는 전체 노드의 비용 초기화
for (int i = 0; i < number; ++i)
{
dist[i] = info[start][i];
}
// start는 이미 검사했으므로 방문 표시
visited[start] = true;
for (int i = 0; i < number - 1; ++i)
{
// 갈수 있는 노드중 가장 최소 비용의 노드부터 검사한다.
int current = GetSmallIndex();
// 이제 검사를 진행 하므로 노드 방문 표시
visited[current] = true;
// 모든 노드를 검사하면서
for (int j = 0; j < 6; ++j)
{
if (!visited[j])
{
// 이전에 가는 비용보다 현재 노드를 거처 가는 비용이
// 더 싼 경우. 비용을 갱신한다.
if (dist[current] + info[current][j] < dist[j])
dist[j] = dist[current] + info[current][j];
}
}
}
}
int main()
{
Dijkstra(0);
for (int i = 0; i < number; ++i) printf("%d ", dist[i]);
}위 코드는 최소 비용을 단순히 선형 탐색으로 찾도록 만들었다. 이 경우 시간 복잡도가 O(N^2)가 된다. 위와 같은 코드는 정점의 갯수가 많은데 간선은 적을 경우 치명적일 정도로 비효율적으로 작동할 수 있다는 단점이 존재한다. 그러면 더 빠르게 작동시키는 경우는 무엇이 있을까?
O(N*logN) 방법
힙 구조를 활용하면 시간 복잡도를 O(N*logN)까지 줄일 수 있다.
코드는 다음과 같다.
#include <iostream>
#include <vector>
#include <queue>
using namespace std;
int number = 6;
int INF = 1000000000;
vector<pair<int, int>> a[7];
int d[7];
void dijkstra(int start)
{
d[start] = 0;
priority_queue<pair<int, int>> pq; // 최대 힙 선언
pq.push(make_pair(start, 0));
// 가까운 순서대로 처리하므로 큐를 사용합니다.
while (!pq.empty())
{
int current = pq.top().first;
// 짧은 것이 먼저 오도록 음수화 합니다.
int distance = -pq.top().second;
pq.pop();
// 최단 거리가 아닌 경우 스킵합니다.
if (d[current] < distance) continue;
for (int i = 0; i < a[current].size(); i++)
{
// 선택된 노드의 인접 노드
int next = a[current][i].first;
// 선택된 노드 거쳐서 인접 노드로 가는 비용
int nextDistance = distance + a[current][i].second;
// 기존의 최소 비용보다 더 저렴하다면 교체합니다.
if (nextDistance < d[next])
{
d[next] = nextDistance;
pq.push(make_pair(next, -nextDistance));
}
}
}
}
int main()
{
// 기본적으로 연결되지 않은 경우 비용은 무한입니다.
for (int i = 1; i <= number; i++)
{
d[i] = INF;
}
a[1].push_back(make_pair(2, 2));
a[1].push_back(make_pair(3, 5));
a[1].push_back(make_pair(4, 1));
a[2].push_back(make_pair(1, 2));
a[2].push_back(make_pair(3, 3));
a[2].push_back(make_pair(4, 2));
a[3].push_back(make_pair(1, 5));
a[3].push_back(make_pair(2, 3));
a[3].push_back(make_pair(4, 3));
a[3].push_back(make_pair(5, 1));
a[3].push_back(make_pair(6, 5));
a[4].push_back(make_pair(1, 1));
a[4].push_back(make_pair(2, 2));
a[4].push_back(make_pair(3, 3));
a[4].push_back(make_pair(5, 1));
a[5].push_back(make_pair(3, 1));
a[5].push_back(make_pair(4, 1));
a[5].push_back(make_pair(6, 2));
a[6].push_back(make_pair(3, 5));
a[6].push_back(make_pair(5, 2));
dijkstra(1);
// 결과를 출력
for (int i = 1; i <= number; i++)
{
printf("%d ", d[i]);
}
} 위 코드는 인접 리스트 방식을 활용하여 시간 복잡도 O(N*logN)으로 구현한 것이다. 이 경우 정점에 비해 간선의 개수가 비정상적으로 적어도 안정적으로 처리할 수 있다.
출력 값

'Algorithm > 이론' 카테고리의 다른 글
| 구간 합(Prefix Sum) 알고리즘 (0) | 2020.07.20 |
|---|---|
| 허프만(Huffman) 트리를 이용한 텍스트 압축 (0) | 2020.07.09 |
| 백트래킹 알고리즘 (Backtracking Algorithm) (0) | 2020.06.30 |
| 플로이드 워셜 알고리즘 (Floyd-Warshall Algorithm) (0) | 2020.06.18 |
| 크러스컬 알고리즘 (Kruskal Algorithm) (0) | 2020.06.17 |

